

In this article, we will look into one of the most popular machine learning algorithms, Logistic regression. Logistic regression is used in classification problems, we will talk about classification problems in the next section. Here, I will try my best to use simple terms so that we can understand what we are talking about. In this article, we will cover below-listed points,
- What is Logistic Regression?
- How do Logistic Regression works?
- Model building using Scikit-learn
Classification problem and Problem definition
What is a classification problem? As the name suggests and in the simplest term, a classification problem used when we have to divide the set of records(data) into several parts. But in this case, we have to divide our data into only two parts based on two values either 1(YES) or 0(NO). Hence this classification problem is also called a binary classification.
Let’s take the example of a clothing company, this company has built a Suit and launched into a market. The company is trying to find out the age group of the customers based on the sales of the suits, for the better marketing campaign. So that company can target only those customers who belong to that age group.
Let’s assume the company has all the orders of the customers in CSV file and they hired you to solve this problem. The company is asking which age group is most likely to buy this suit? No clue!
Well, we will create a model to solve this problem in the post and we will understand how we can use logistic regression in this situation.
Logistic Regression
Just a heads up, if you have never used linear regression before, I would recommend you to read Simple Linear regression algorithm in machine learning.
Am not a big fan of Showing Complex Math equations and theory. But again, you need fundamental knowledge of Math in order to understand Math behind these algorithms. Okay, let’s start with Logistic Regression.
Logistic Regression is a specific type of linear regression. What I mean by this is, It applies a sigmoid function to the linear regression equation, so that data set can be classified into two parts. Let’s take a look at the equation of linear regression,
y = B0 + B1*x
where,
y is a dependent variable.
B0 is the Y intercept, where best-fitted line intercept with Y axis.
B1 slope co-efficient.
x is independent variable.
If you look at the Sigmoid function it looks like this,
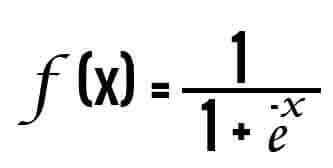
After applying this sigmoid function on linear regression equation, you will get the below-shown equation,

Graphical representation of Logistic Regression
The graph of Linear regression is very straightforward and easy to understand. We are very much familiar with the Linear regression, which is displayed below,
After the applying sigmoid function to the linear regression, your graph will look like a below-shown graph,

Now you know how Machine learning logistic regression looks like. But again, a question pops into our mind! How would I classify the data sets into two parts?
I assume we are aware of our problem description (take a look at Classification problem and Problem definition section). Let me describe this graph based on our problem description. Take a look at below graph, First, let’s see what we have here,
First, let’s see what we have here,
- The red dots are representing users, these users may or may not buy the suits.
- The X-axis represents the Age of the users.
- The Y-axis represents the Salary of the users.
- The green line is representing the dependent variable y with value 1.
- (Assume there is) The yellow dotted line is dividing the graph into two parts equally.
According to our assumption, we have a yellow dotted line dividing the graph into two parts equally. Now the logistic regression will classify the data into two parts based on this line.
=> The users which fall below the Yellow line won’t buy the suits. This means that there is a high probability these users won’t buy the suits.
=> The users which are above the yellow line will most likely buy the suits. These users have a high probability of buying the suits.
Preparing the data for training
Now we are aware how Logistic regression works. The next step is to prepare the data for the Machine learning logistic regression algorithm. Preparing the data set is an essential and critical step in the construction of the machine learning model.
To predict the accurate results, the data should be extremely accurate. Then only your model will be useful while predicting results. In our case, the data is completely inaccurate and just for demonstration purpose only. In fact, I wrote Python script to create CSV. This CSV has records of users as shown below,

You can get the script to CSV with the source code.
The Machine learning logistic regression model
=> To import this file and to use the data inside the file, we willpandas python library. To implement the Simple linear regression model we will use thescikit-learn library.
=>Now let’s create a model to predict if the user is gonna buy the suit or not. The first step to construct a model is to create import the required libraries.
=> Create filelogistic_regression_super_mall.py and write down the below code.
logistic_regression_super_mall.py:
# -*- coding: utf-8 -*- """ Created on Sat Dec 29 23:10:15 2018 Machine learning logistic regression in python with an example @author: SHASHANK """ # Importing the libraries import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression
=>Now we will create a class calledModelshown below. In this class, we will create three methods.
logistic_regression_super_mall.py:
# -*- coding: utf-8 -*-
"""
Machine learning logistic regression in python with an example
@author: SHASHANK
"""
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
# Applying feature scaling on the train data
def doFatureScaling(self):
def predictAge(self):
# we will call importData(), in order to import the test data.
self.importData()
# We will call doFatureScaling() for scaling the values in our dataset
self.doFatureScaling()
=>Now let’s import the data set in ourmodelclass. Under theimportData()method add the below code as shown below,
logistic_regression_super_mall.py:
# -*- coding: utf-8 -*-
"""
Machine learning logistic regression in python with an example
@author: SHASHANK
"""
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
dataset = pd.read_csv('supermall.csv')
self.X = dataset.iloc[:, [2,3]].values
self.Y = dataset.iloc[:, 4].values
# Applying feature scaling on the train data
def doFatureScaling(self):
def predictAge(self):
# we will call importData(), in order to import the test data.
self.importData()
# We will call doFatureScaling() for scaling the values in our dataset
self.doFatureScaling()=> The next step of the creating a model is to add feature scaling on our data set. We will usescikit-learn libraryfor feature scaling. We have already imported a library for it. Let’s use that library to do the feature scaling.
logistic_regression_super_mall.py:
# -*- coding: utf-8 -*-
"""
Machine learning logistic regression in python with an example
@author: SHASHANK
"""
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
dataset = pd.read_csv('supermall.csv')
self.X = dataset.iloc[:, [2,3]].values
self.Y = dataset.iloc[:, 4].values
# Applying feature scaling on the train data
def doFatureScaling(self):
self.standardScaler = StandardScaler()
self.X = self.standardScaler.fit_transform(self.X)
Explanation:
- In our dataset, we have huge numeric values for the salary field. Feature scaling will normalize our huge numeric values into small numeric values.
- Let’s say if we have billions of records in our dataset. If we train our model without applying Feature scaling, then the machine will take time too much time to train the model.
- in our code first, we will create an object of
StandardScalerand then we willfit_transform()method on our data.
=> Let’s add the code underisBuying()method. In this method, we will add code to fit the train data that we have already have. Also, we will take input from the user and based on that input our model will predict the results. So in the end, your model should look like this:
logistic_regression_super_mall.py:
# -*- coding: utf-8 -*-
"""
Machine learning logistic regression in python with an example
@author: SHASHANK
"""
# Importing the libraries
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
dataset = pd.read_csv('supermall.csv')
self.X = dataset.iloc[:, [2,3]].values
self.Y = dataset.iloc[:, 4].values
# Applying feature scaling on the train data
def doFatureScaling(self):
self.standardScaler = StandardScaler()
self.X = self.standardScaler.fit_transform(self.X)
def isBuying(self):
self.importData()
self.doFatureScaling()
# Fitting the Simple Linear Regression to the Training set
classifier = LogisticRegression(random_state = 0)
classifier.fit(self.X, self.Y)
userAge = float(raw_input("Enter the user's age? "))
userSalary = float(raw_input("What is the salary of user? "))
# Applying feature scaling on the test data
testData = self.standardScaler.transform([[userAge, userSalary]])
prediction = classifier.predict(testData)
print 'This user is most likely to buy the product' if prediction[0] == 1 else 'This user is not gonna buy the your product.'
Explanation: In isBuying() method,
- We will call
importData()anddoFatureScaling()methods. - Then we are fitting out dataset to the Logistic Regression algorithm by using
LogisticRegressionlibrary. - Then using python we are asking for inputs from the user as a Test data.
- After receiving inputs from the user, we will apply feature scaling on the inputs.
- Lastly, we are predicting the values using
classifier.predict()method.
Executing the Model
Now your model is complete and ready to predict the result. To execute the model we will call the isBuying() method of the class model as shown below,
# -*- coding: utf-8 -*- """ Machine learning logistic regression in python with an example @author: SHASHANK """ model = Model() model.isBuying()
Conclusion
This section brings us to the end of this post, I hope you enjoyed doing the Logistic regression as much as I did. The Logistic regression is one of the most used classification algorithms, and if you are dealing with classification problems in machine learning most of the time you will find this algorithm very helpful.
Also, I will urge you to learn the math behind Logistic regression from google. By doing so, you will understand how it works and what is the logic behind the algorithm. So, for now, that’s it from my side.
If you like this article share it on your social media and spread a word about it. Till then, happy machine learning.




