

With this article, we will make one more step towards learning Machine Learning. This post will explain you, Support Vector Machine Machine learning algorithm with example and code in python.
In Machine learning, there are various algorithms. To become an expert in machine learning, one must know when and where to use which machine learning algorithms. So, today we will talk about the Support Vector Machine algorithm, where and when to use this algorithm. In this article, we will cover below-listed points,
- What is Support Vector Machine?
- How do Support Vector Machine works?
- We will build a model using Support Vector Machine
Classification problem and Problem definition
What is a classification problem? As the name suggests and in the simplest term, a classification problem used when we have to divide the set of records(data) into several parts.
Let’s take the example of a clothing company, this company has built a Suit and launched into a market. The company is trying to find out the age group of the customers based on the sales of the suits, for the better marketing campaign. So that company can target only those customers who belong to that age group.
Let’s assume the company has all the orders of the customers in CSV file and they hired you to solve this problem. The company is asking which age group is most likely to buy this suit? No clue!
Well, we will create a model to solve this problem in this post and we will understand how we can use SVM algorithm in this situation.
What is Support Vector Machine?
Support Vector Machine algorithm is a supervised machine learning algorithm. You can also refer Support Vector Machine to SVM for short. SVM algorithm can solve classification and regression operations. Although, the SVM algorithm is popular for solving classification operations. SVM performs best on smaller datasets and can give you incredible and accurate predictions.
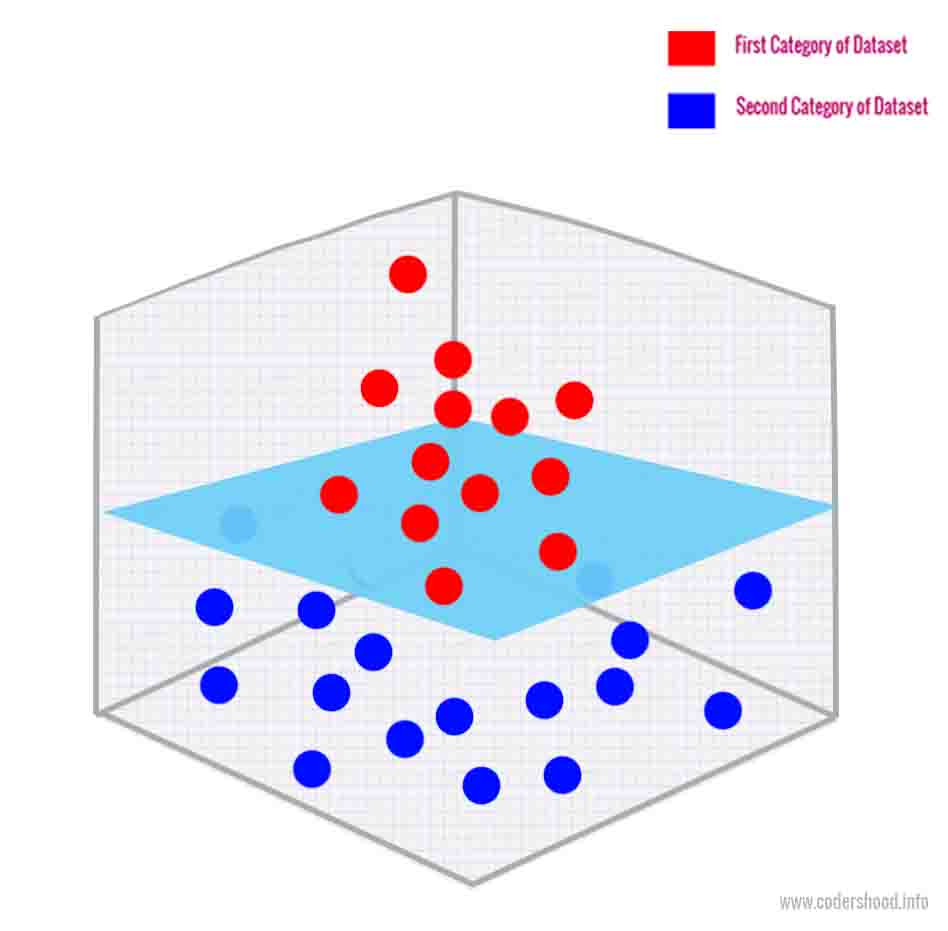
The main task of SVM is to find a Hyperplane between datasets in n -dimensions to classify the datasets. Here, n stands for the number of features in the dataset.

In the above graph, the blue and red circles represent our dataset. With the help of SVM, we will classify this dataset into separate two separate categories. These datasets are classified by a hyperplane, as shown in the graph. The hyperplane divides the datasets with the help of Support Vectors. Let’s understand how the SVM algorithm creates the hyperplane and Support Vectors.
- In the multidimensional plane, we refer these points(unique data in a dataset) as Vectors.
SVM algorithm first calculates maximum margin using two closest opposing vectors. - After that, the maximum margin distance is divided into two parts in order to find the Hyperplane.
- The Hyperplane is equidistance from the selected opposing vectors, hence these vectors are called as Support Vectors.
- Since this algorithm is completely dependent on the support vectors, therefore it’s named as Support Vector Machine.
Types of Kernel in SVM and the Kernel Trick
The above dataset was linearly separable although this not a usual case. As a machine learner, our lives are not always that much simple. What if we have non-linearly separable dataset then? For example, the below graph shows the dataset plotted on Two Dimensions. In Two Dimensions the below-shown dataset is impossible to separate linearly.

Well, in this case, the solution is projecting these datasets in a higher dimension. After projecting these datasets, we can apply the SVM algorithm.
In the below multi-dimensional graph, we have introduced a new dimension. And these dataset is separated by a plane instead of a line.
I know, this all sounds good in theory but how would you implement this in practice! To save us from this trouble we have something called The Kernel Trick. When we apply the SVM algorithm using the scikit-learn library, then we can specify what type of Kernel we want to classify the datasets.
With the help of specified Kernel, the SVM algorithm automatically does the job for us. There is four most used SVM kernel out there as far as I know, which I have listed below,
- Linear Kernel
- Polynomial Kernel
- Gaussian (RBF) Kernel
- Sigmoid kernel
In this post, we will use two types of kernels i.e. Linear Kernel and RBF Kernel.
Preparing the data for training
Now we are aware how SVM algorithm works. The next step is to prepare the data for the Machine learning SVM algorithm. Preparing the data set is an essential and critical step in the construction of the machine learning model.
To predict the accurate results, the data should be extremely accurate. Then only your model will be useful while predicting results. In our case, the data is completely inaccurate and just for demonstration purpose only. In fact, I wrote Python script to create CSV. This CSV has records of users as shown below,

You can get the script to CSV with the source code.
Support Vector Machine Machine learning algorithm with example
=>To import this file and to use the data inside the file, we will usepandas python library. To implement the SVM model we will use the scikit-learn library.
=>Now let’s create a model to predict if the user is gonna buy the suit or not. The first step to construct a model is to create import the required libraries.
=>Create filesvm_super_mall.pyand write down the below code.
svm_super_mall.py:
# -*- coding: utf-8 -*- """ Support Vector Machine Machine learning algorithm with example @author: SHASHANK """ # Importing the libraries import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC
=>Now we will create a class called Modelshown below. In this class, we will create three methods.
svm_super_mall.py:
# -*- coding: utf-8 -*-
"""
Support Vector Machine Machine learning algorithm with example
@author: SHASHANK
"""
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
# Applying feature scaling on the train data
def doFatureScaling(self):
def isBuying(self):
# we will call importData(), in order to import the test data.
self.importData()
# We will call doFatureScaling() for scaling the values in our dataset
self.doFatureScaling()=>Now let’s import the data set in ourmodel class. Under theimportData() method add the below code as shown below,
svm_super_mall.py:
# -*- coding: utf-8 -*-
"""
Support Vector Machine Machine learning algorithm with example
@author: SHASHANK
"""
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
dataset = pd.read_csv('supermall.csv')
self.X = dataset.iloc[:, [2,3]].values
self.Y = dataset.iloc[:, 4].values
# Applying feature scaling on the train data
def doFatureScaling(self):
def isBuying(self):
# we will call importData(), in order to import the test data.
self.importData()
# We will call doFatureScaling() for scaling the values in our dataset
self.doFatureScaling()=>The next step of the creating a model is to add feature scaling on our data set. We will usescikit-learn libraryfor feature scaling. We have already imported a library for it. Let’s use that library to do the feature scaling.
svm_super_mall.py:
# -*- coding: utf-8 -*-
"""
Support Vector Machine Machine learning algorithm with example
@author: SHASHANK
"""
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
dataset = pd.read_csv('supermall.csv')
self.X = dataset.iloc[:, [2,3]].values
self.Y = dataset.iloc[:, 4].values
# Applying feature scaling on the train data
def doFatureScaling(self):
self.standardScaler = StandardScaler()
self.X = self.standardScaler.fit_transform(self.X)Explanation:
- In our dataset, we have huge numeric values for the salary field. Feature scaling will normalize our huge numeric values into small numeric values.
- Let’s say if we have billions of records in our dataset. If we train our model without applying Feature scaling, then the machine will take time too much time to train the model.
- In our code first, we will create an object of
StandardScalerand then we willfit_transform()method on our data.
=>Let’s add the code underisBuying()method. In this method, we will add code to fit the train data that we have already have. Also, we will take input from the user and based on that input our model will predict the results. So in the end, your model should look like this:
svm_super_mall.py:
# -*- coding: utf-8 -*-
"""
Support Vector Machine Machine learning algorithm with example
@author: SHASHANK
"""
# Importing the libraries
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
class Model:
X = None
Y = None
standardScaler = None
# Importing the dataset
def importData(self):
dataset = pd.read_csv('supermall.csv')
self.X = dataset.iloc[:, [2,3]].values
self.Y = dataset.iloc[:, 4].values
# Applying feature scaling on the train data
def doFatureScaling(self):
self.standardScaler = StandardScaler()
self.X = self.standardScaler.fit_transform(self.X)
def isBuying(self):
self.importData()
self.doFatureScaling()
# Fitting Gaussian (RBF) Kernel SVM to the Training set
classifier = SVC(kernel = 'rbf', random_state = 0)
# Fitting Linear Kernel SVM to the Training set
# classifier = SVC(kernel = 'linear', random_state = 0)
classifier.fit(self.X, self.Y)
userAge = float(raw_input("Enter the user's age? "))
userSalary = float(raw_input("What is the salary of user? "))
# Applying feature scaling on the test data
testData = self.standardScaler.transform([[userAge, userSalary]])
prediction = classifier.predict(testData)
print 'This user is most likely to buy the product' if prediction[0] == 1 else 'This user is not gonna buy the your product.'
Explanation:InisBuying()method,
- We will call
importData()anddoFatureScaling()methods. - Then we are fitting our dataset to the SVM algorithm by using
SVMclass. - If you notice, here we have RBF kernel to train our model. If you want to use any other kernel you can use it by providing the name of the kernel.
- For example, in the next commented line we have used the linear kernel to train the model.
- I urge you uncomment it and try to have fun with it, you can find much better results by doing some parameter tuning, although the focus should be on creating a more generalized model that can be used on any dataset.
- Then using python we are asking for inputs from the user as a Test data.
- After receiving inputs from the user, we will apply feature scaling on the inputs.
- Lastly, we are predicting the values using
classifier.predict()method.
Executing the Model
Now your model is complete and ready to predict the result. To execute the model we will call theisBuying()method of the class model as shown below,
# -*- coding: utf-8 -*- """ Support Vector Machine Machine learning algorithm with example @author: SHASHANK """ model = Model() model.isBuying()
Conclusion
For now that’s it for Support Vector Machine Machine learning algorithm. I hope you understood the Support Vector Machine algorithm and their two different types of Kernels. The SVM algorithm can be one the most powerful tool that you can use to solve your machine learning problem.
Also, I will urge you to learn the math behind SVM algorithm using Google. By doing so, you will understand how it works and what is the logic behind the algorithm. So, for now, that’s it from my side.
If you like this article share it on your social media and spread a word about it. Till then, happy machine learning.




